
Nobody knows and I’m not going to pretend to tell you. However, in this post, I’d like to lay out the basic numbers as we pretend to know them about overall bird mortality, human related causes of mortality, and somewhere in there I’ll note that the number of birds that are killed by windmills is so small that it says “zero” on my pie chart. Having said that, we expect wind mills to increase in number, and the specific birds that are killed by them may be a particularly sensitive group (i.e. eagles and vultures) so we need to pay attention. Having said that, I would like to note that we need to keep the fossil carbon in the ground. Climate change is an existential threat to humans and birds alike. So keep that in mind.
How many birds are there in the US?
According to the US Fish and Wildlife Service, there are about 10 billion breeding birds in the US. I can confirm that other sources I’ve read give similar numbers. The maximum population size may be closer to 20 billion in the fall, and 10 billion at the start of the Spring breeding season. In other words, looking at fledglings (or older) and not chicks, the US bird population normally doubles itself every year, but then get undoubled by … well, various factors probably mostly hypothermia, starvation, disease, and predation.
A certain number of these deaths are caused by humans, directly or indirectly.
How many birds to cats kill in the United States?
A recent meta study (The impact of free-ranging domestic cats on wildlife of the United States) that applied strict inclusion criteria and some fancy statistics estimates that 2.4 billion birds, plus or minus more than a billion, are killed by cats every year in the US. Notably, this is a vey small number compared to the number of rodents killed by the same cats. While cats do not fill a specific niche normally held by a native carnivore, there are reasons to believe that some of those birds would have been eaten by a wild predator had the cats not been in play. Also, in relatively natural, or wild, lands in much of the US the feral cat population will be limited by a healthy wild predator population. In other words, cats may be a very severe problem in some places, but in other places not a factor at all.
If this study is accurate (and I do not vouch for it at this time but it is a real study) cats take out about one tenth of those 10 billion birds that disappear between peak seasons. Most likely they are smaller birds, and one would hope they are common birds (statistically they should be) but locally there could be some real stress on rare bird populations from cats. And, importantly, an unknown number of these birds likely would have been eaten by a different predator had a cat not gotten them first. For various reasons including these I would regard this estimate to be effectively high.
How many birds are killed in building strikes?
This is understudied, and we really don’t have a good estimate, in my mind. But the US Fish and Wildlife Service estimates between 97 and 976 million a year. So at worst, another billion from building strikes. Or may be a tenth of that.
It is possible but highly unlikely that a bird that runs into a window would have run into a rock anyway. Buildings (and other structures, see below) pose a novel threat to birds without an analog in nature. Perhaps a subset of birds are killed this way; maybe birds learn to avoid windows in their home ranges, and only the careless or stupid birds hit the window and die. That would be an interesting study. I would not expect this effect to be very large though.
What are other human causes of bird death?
Habitat destruction is probably the biggest threat to birds, but here we are talking more about specific birdicide events rather than the larger scale problem of humans simply taking the planet away from everybody else.
A small number, maybe about 72 million according to the US Fish and Wildlife Service, are poisoned every year.
By-catch is the catchy word for animals that are killed from fishing that are not the fish being fished. These are the dolphins in your tuna fish, for example. By-catch kills between tend to hundreds of thousands of birds in the US every year, again, a vague and rough estimate. This is a small number given the total number of birds, but since these are only sea birds, which make up only a fraction of the 10 to 20 billion US birds, it may be a rather large number especially for threatened populations.
Communications towers kill between 4 and 50 million birds a year (US Fish and Wildlife Service)
High tension line strikes kill tens of thousand annually, as do electrocutions on power lines. About 60 million birds are hit by cars a year, and several thousands die from being hit with airplanes.
About 15 million birds are killed annually by hunters, and of course this is distributed among a very small number of species. Wind mills may kill about 33,000, though there are countless problems with this kind of study and we really have no idea what this number is. Oil and wastewater pits, and oil spills kill about 2 million birds a year in the US (Sibley)
So, to summarize:
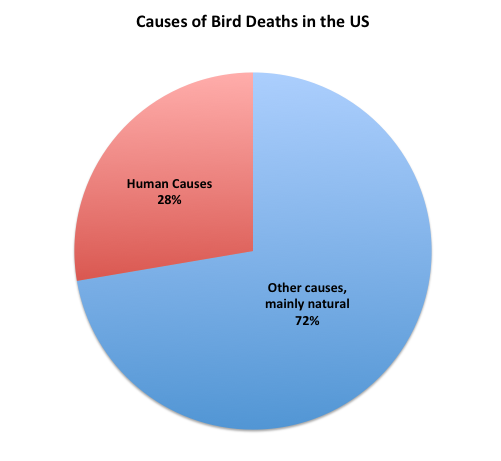
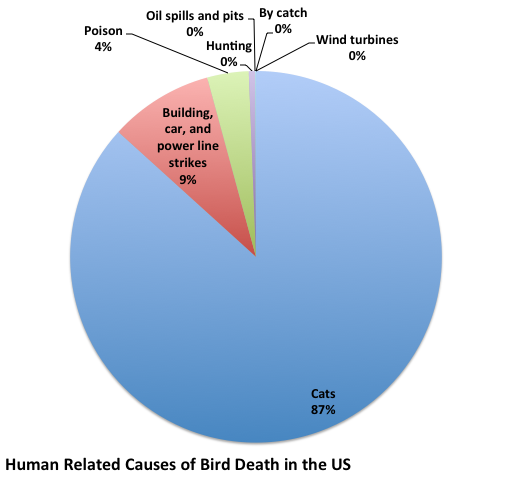
Why is all of this of little importance?
As a reader of 10,000 Birds you weren’t hatched yesterday when it comes to birds. Imagine the following choice, you get to make because you have an evil fairy godmother. You have to kill some birds. There are two different numbers of birds that will be killed on your behalf, and you get to chose the number. The number will be either 5 billion or 10,000.
The difference is, if you pick 1 billion, the dead birds will be randomly distributed among the most common 10 species. If, however you pick the 10,000 number, they will be randomly distributed among the lest common 10 species.
Clearly the second choice will cause some species to go extinct, most likely. You will be wiping out the whooping cranes, taking down the golden eagles, aborgating a handful of rare warblers. The first choice will kill a lot of starlings.
The other day somebody decided that the Audubon Society would be ignored in their request to change the color of the huge clear glass wall that will grace a large part of the outside of the new Vikings Stadium. The fact that that Audubon society and others had to push for this is absurd. Bird strike effects should be a standard part of environmental impact assessments for any new project. I would be they are in less environmentally backwards states (and I say that with some authority having done EIS work in several states … Minnesota is the wild west when it comes to environmental protection). We should not be comparing how many birds are killed by wind turbines or buildings based on essentially useless data. We should be doing more studies and including assessments in all new projects. Also, the comparison with cats is not particularly relevant. Cats are not the same thing as windmills. They will kill very different species, and they have very different mitigation possibilities.
The main point of this post is to indicate that the problem of windmills and other alternate energy projects is very small compared to other problems. Having said that, I think that if it is true that about 28% of all bird deaths in the US are human-linked, that we need to pay more attention to what we are doing. Having said that I think we need to assess the cat number more carefully (I think it is too big) and start dividing all of these data up among at least general categories of birds, rather than taking all birds as the same, because they are not.










you also have to understand, when you talk about wind farms, that they are not required to report bird and bat kills in many areas. some states require eagle kills be reported but no otherr birds. So while this number appears to be small, there’s really no level of accuracy in that number.
Thanks for the summary. Tangential to the topic is information I gathered from a young biologist who was studying bats and wind turbines. She was finding dead bats with ‘exploded’ lungs, her belief was that bats died when caught in the pocket of low pressure behind a turning blade, their lungs couldn’t deal with the pressure difference.
Great post. I think of this kind of analysis as a starting point – now you have a framework against which to work, if you wanted to start refining these numbers. Perhaps some are wrong, but at least you have a rough idea of the relative size of various effects.
Yes, the numbers for bird kills from wind facilities are almost certainly wrong, but the key question is “how wrong”. If you assume that only a tenth of the facilities require reporting, and that only a tenth of the bird kills are actually detected, and then further assume that bad operators are intentionally fudging the numbers by reporting only a tenth of what they know about (all pretty big assumptions in favor of your thesis), you’re still only talking about this estimate being off by 3 orders of magnitude, which puts it at about 33M, roughly twice what hunters take (and still not enough to show up on our chart).
And that’s before you consider, as the linked paper does, the relative kills between power generated from wind and power generated from fossil fuels: it may well be that switching a GW of generation capacity from coal to wind actually results in a net *reduction* in bird kills. In other words, that’s how little we know about the number of bird kills from wind on a net basis – we don’t even really know the *sign* of the number. And, that’s before you consider effects of habitat loss: how many birds lose out when you strip mine coal in Wyoming? When you spill oil in the Gulf of Mexico? When you, ultimately, heat up their habitat so much they can’t use it any more?
Great post.
Carolyn H.: That is a very important point. I think the effects of human activities on birds should become part of the standard reporting.
Peter: Interesting. Bats are a whole ‘nuther, very important, issue.
Kenneth, exactly. I strongly suspect that in terms of overall numbers, switching to clean energy is a net win for birds. But, within that shift, there are likely to be situations where specific species of birds are more at risk. Also, there are things that can be done to reduce the effects of windmills.
It isn’t just raptors and bats, though. Another criticism of wind turbines is that they often locate in deep forest sites, then clearcut large diameters around each turbine, and large swaths next to access roads. Which turns deep forest into not-so-deep forest, and affects all the animals living there.
Thanks Greg. I would also suggest that we need to factor in climate change impacts to bird mortality and consider that human induced.
If we stay the stays quo and x species become extinct or degraded how would that compare to a y increase in the windmills needed to slow down climate change ?
It would be great to run these numbers so people start to see the impacts of doing little
Judy, I agree.
I also wonder, though, if impacts need to be categorized broadly into more than one category that has to do with the specific nature of the impact. I sense that there is a difference between things like cat hunting, humans hunting, windmill or building kills, etc. on one hand vs. habitat loss and environmental change on the other. Sort of like the difference between a concrete noun and an abstract noun. This is not to say that there is a difference in the importance of level of impact, but there are differences in how to address them, and how to measure them.
This is fascinating and well-written stuff, Greg; I’ll be bookmarking it for future use. One question: Any thoughts on how migratory species (that is, those which pass through the U.S. twice a year but don’t breed here) factor in? My anecdotal experience is that they’re the lion’s share of window-collision deaths, as opposed to “townies” like robins and starlings and House sp. Any data on how migrants are impacted, perhaps differently than locals, by the threats you cite?
Greg,
All people want to try to fix problems when they see them, especially when the problem is an unusually large one. So what are you doing to help? Now I don’t know you as a person, so don’t think that this entire comment is targeted at you. I feel the need to post the following disclaimer because I DO NOT wish to seem aggressive and begging for a fight (although I have no doubt that others will take it this way anyways, they usually do). Some of my points may apply to you while others may not. However- the points I make in this comment go for many people that I have encountered in the past. That said, here goes…
Perhaps people who believe that ‘communication towers’ are killing too many bird species should get rid of their cell phones and urge others to do the same so that they are not indirectly contributing to the ‘communication towers’ that are killing so many birds annually. But that wouldn’t be easy to do, so it probably wouldn’t happen.
And I don’t even know what to do about your houses. Perhaps go without windows altogether?
And the cats! I almost forgot about the cats! What about them? It’s funny how when folks see a ‘problem’ (I use the term loosely), in this case a large number of creatures (birds) dying, part of the solution is many times killing a large number of another creature (cats), when 9 times out of 10 if asked, most people would be ‘against’ killing any kind of creature. Of course once the situation becomes uncomfortable for them, (say because cats are killing the very birds you watch) all of those no-kill ‘values’ go right out the window.
And lastly (I think), there is the ever-looming dilemma of wind turbines. Another great paradox. People get gung-ho on developing ‘green’ sources of energy to help save the environment (because it apparently does need to be saved), but then when a method is developed, the very folks who wanted it are now against it because it is killing to many birds. Try to figure that one out.
And of course there is overpopulation (I almost forgot!). But people who believe in overpopulation can never under any circumstances argue about human overpopulation with any credibility, because their very being here blows their own argument out of the water. Shouldn’t they do something about overpopulation? Oh, of course they think something should be done—with others, not themselves.
PS
One estimate (http://www.abcbirds.org/abcprograms/policy/cats/pdf/Loss_et_al_2013.pdf) is billions of birds per year killed by cats, yet the FWS (http://www.fws.gov/birds/mortality-fact-sheet.pdf) has a much smaller estimate of about 39 MILLION.
Communication towers kill 4-5 million birds a year, not 4-50 million (http://www.fws.gov/birds/mortality-fact-sheet.pdf)
97-976 million is an absolutely HUGE gap, so basically people has no idea and just through numbers out there.